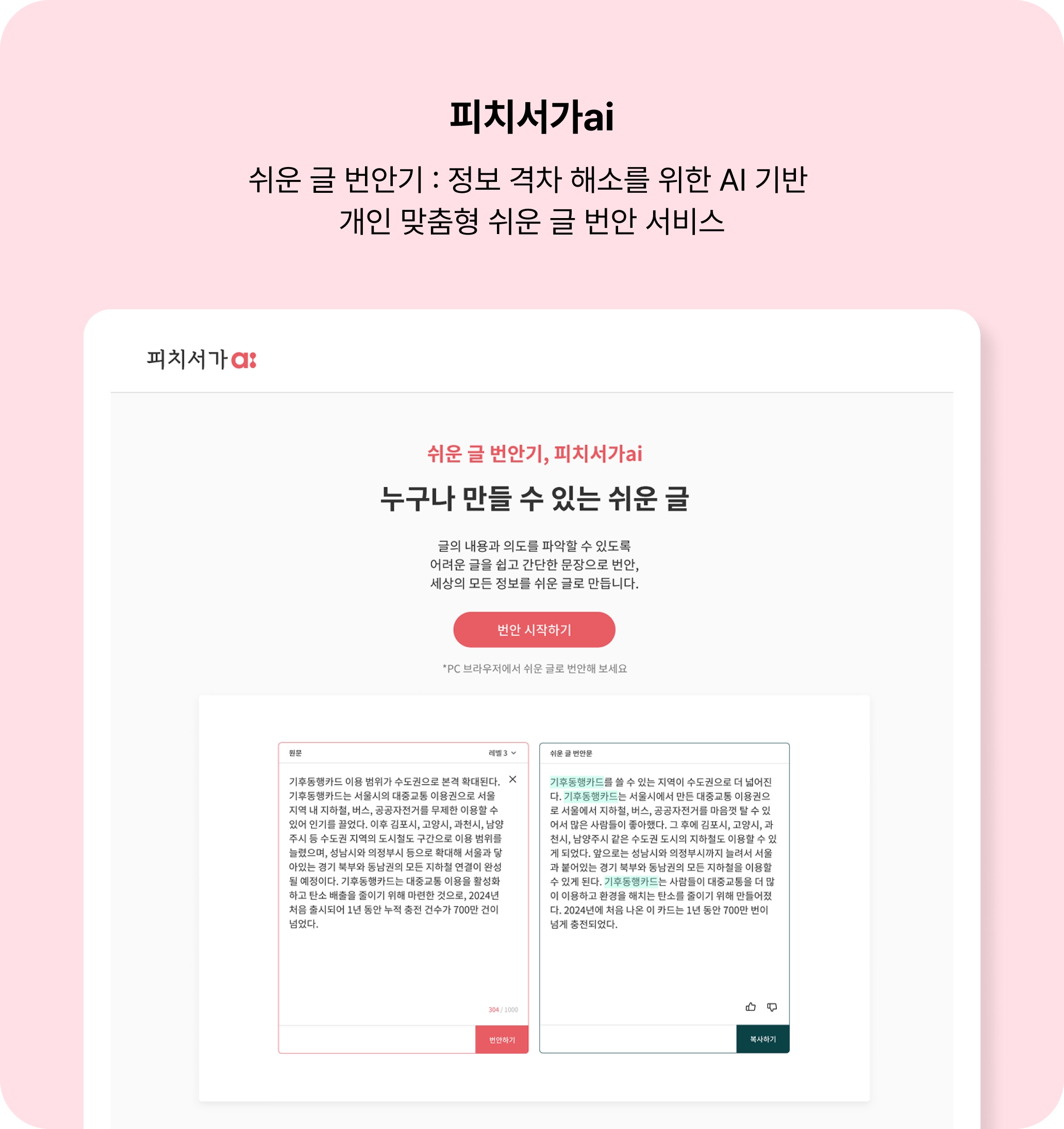
Can LLMs bridge the information gap for slow learners? — This was the guiding question behind 피치서가ai a service that uses AI to generate text tailored to each reader’s comprehension level across five linguistic dimensions.
Context: Tech for Impact & B-Peach LAB

Tech for Impact is a technology initiative by Kakao Impact Foundation (the corporate foundation of Kakao) that connects social innovators with IT professionals to build technology that drives real social change. It runs through a format called LABs — 6-month collaborative projects where working professionals volunteer weekly alongside nonprofits.
I participated in B-Peach LAB Season 2 partnered with Peach Market (피치마켓) — a Korean social enterprise that produces accessible content for people with intellectual and developmental disabilities. Peach Market’s mission is straightforward but urgent: information is the most fundamental resource for navigating life yet millions of slow learners are cut off from it because the written world simply isn’t designed for them.
I was on the AI engineering team and as the project evolved I became the sole developer responsible for the entire AI backend — architecture design backend integration prompt engineering observability latency experiments and cross-team communication.
This post is a technical retrospective of what I built what I learned and what I’d do differently.
The Problem
Information is the foundation of how we understand the world form values and make decisions. But for millions of people — those with intellectual disabilities developmental disabilities limited education or simply unfamiliar with specialized domains — the written information around them is inaccessible. Government notices news articles textbooks literary works even basic service instructions become barriers rather than bridges.
Peach Market had been addressing this through manual “easy language” translation but human editors can only process so much. The Season 1 LLM tool helped but it offered only a single one-size-fits-all difficulty level. A text simplified for a 7-year-old reader is useless for a teenager with mild learning difficulties — it strips too much nuance. Conversely a mildly simplified version still walls out readers who need more fundamental restructuring.
We needed a system that could systematically control how text gets simplified across multiple dimensions grounded in reading comprehension theory — not just “make it easier” but “make it easier in these specific ways to this specific degree.”
Architecture: From Monolith to Modular Domain Separation
Identifying the Problem Early
When I joined the codebase was a single FastAPI application with all business logic crammed into services/service.py. I raised the first refactoring proposal early on:
- Domain logic was entangled with backend plumbing. LLM orchestration prompt management and API response formatting all lived in the same file.
- No dependency injection. Objects were instantiated directly inside routers making unit testing impossible — only integration tests existed.
- No room to grow. Future features like my team mentioned(RAG graph databases or multi-step pipelines) would turn the service layer into an unmanageable monolith.
The Redesign
I designed and proposed a new architecture that cleanly separated concerns:
ai-api-v2/
├── ai/ # AI domain layer (pure business logic)
│ ├── core/ # Interfaces base classes shared contracts
│ │ ├── base_usecase.py
│ │ └── infra/
│ │ └── model_router.py
│ ├── single_turn/ # v1 simplification module
│ │ ├── usecase.py
│ │ └── service.py
│ ├── multi_strategy/ # v2 multi-strand simplification
│ │ ├── domain/
│ │ │ ├── entity/
│ │ │ └── constants.py
│ │ ├── components/
│ │ └── usecase.py
│ └── e2e/ # Domain-level entry point + DI container
│ ├── di/
│ │ ├── config.py
│ │ └── container.py
│ └── main.py
├── server/ # Server layer (FastAPI knows nothing about AI internals)
│ ├── api/
│ │ ├── main.py
│ │ └── routers.py
│ └── middleware/
│ └── logging.py
└── tests/
Key design decisions:
- Fixed dependency direction:
server → ai.e2e.main → ai/*. The server layer never imports AI internals directly. The AI domain doesn’t know FastAPI exists. - Domain-owned assembly: Which implementation to use (single-turn multi-strategy future RAG) is decided by
ai/e2enot by the server. Swapping or composing use cases requires zero server changes. - DI container: A
Containerclass centralizes object creation — LLM clients use cases components — making it trivial to mock for testing. - Testability by design: Each module can be tested in isolation. No more spinning up the entire server just to verify prompt logic.
Before implementing I walked the team through the redesign rationale collected feedback and iterated on the proposal. After the refactor I wrote development guidelines so teammates could add new modules following a consistent pattern.
The “팔만대장경” Prompt System
The core innovation of this project was the prompt architecture which we internally called 팔만대장경 — a reference to the Tripitaka Koreana a massive collection of Buddhist scriptures. The name reflected the ambition: a comprehensive systematic framework for text simplification.
Theoretical Foundation: The Reading Rope
We grounded our approach in Scarborough’s Reading Rope model which decomposes reading comprehension into five intertwined “strands”:
| Strand | What It Controls |
|---|---|
| Background Knowledge | Implicit world knowledge needed to understand context |
| Vocabulary | Word-level complexity — technical terms Sino-Korean words abstractions |
| Language Structure | Sentence complexity — subordinate clauses passive voice pronoun resolution |
| Verbal Reasoning | Inference metaphor implied causality |
| Literacy Knowledge | Genre awareness text organization signal words |
Each strand has three levels (A B C) representing different reader profiles. The combination of strand levels forms a strategy profile that determines which “tools” the LLM receives. The LLM receives a dynamically assembled prompt containing only the predefined tools relevant to the reader’s profile.
I participated in the research sessions where the team mapped the Reading Rope strands to Korea’s national Korean language education standards classifying comprehension benchmarks by strand and level. This theoretical mapping became the backbone of our tool definitions.
Cross-Team Integration
Backend Communication
I took ownership of understanding and documenting how the AI server connected to the backend (Spring Boot). There were limited documentation so I traced the end to end request flow by reading both codebases:
Backend (Spring Boot) → Port 8080 → Nginx Proxy (80→8000) → FastAPI Container
I then proposed and implemented DTO changes to clean up the contract between teams:
- Removed model config from the request. Previously the backend was sending model names and temperature settings. I moved all model configuration to the AI team’s domain managed via Langfuse prompt versioning.
- Added
user_idandrequest_idto the schema. Essential for future data pipelines and tracing. - Simplified the response format with explicit field names (
simplified_textinstead of nestedchoices[0].message.content).
I documented every change communicated it to the backend team and coordinated the integration testing timeline.
Infrastructure Team
After the refactor moved the codebase to a new repository (ai-api → ai-api-v2) I coordinated with the infrastructure team for CI/CD setup. I set up GitHub Actions workflows for linting and container testing and worked with infra to get the new images deployed.
Frontend Team: The Adaptation Prevention Tag Problem
The frontend team needed certain HTML spans to pass through the LLM untouched (e.g. proper nouns marked with <prevent-adaptation> tags). The naive approach — regex string matching — was fragile.
My solution:
- Parse the input as HTML (not regex) to extract prevention tags.
- Replace UUID-based tag IDs with sequential integers before sending to the LLM. UUIDs consume excessive tokens and are prone to LLM hallucination; integer IDs are compact and stable.
- Restore original UUIDs in the output by reverse-mapping.
This approach was informed by known best practices for UUID handling in LLM contexts and solved the problem without requiring changes from other teams.
Observability and Latency
Logging Architecture
I led the effort to define a structured logging standard for the AI team. After discussions with the backend team about unified tracing I designed a phased approach:
- Phase 1 (implemented): JSON-structured logs via
python-json-loggeroutput to Docker stdout. Fields:request_idroutelatency_total_msprovidermodel_nmtoken countsuser_idtimestamp. - Phase 2 (proposed): OpenTelemetry-based distributed tracing across backend and AI services visualized in Langfuse.
- Phase 3 (proposed): Prometheus + Grafana for system-level metrics; Loki for log aggregation.
I wrote the detailed implementation proposals for each phase including code samples for both the Spring Boot and FastAPI sides and presented trade-offs to the team. While the full stack wasn’t implemented (the team was constrained by time — this was a side project for working professionals) the structured logging in Phase 1 shipped and became the foundation for debugging in production.
Latency Experiments
The LLM call was the dominant bottleneck — median response times around 12 seconds with P99 hitting 30+ seconds. I ran systematic experiments to find actionable improvements:
Experiment 1: Anthropic Direct vs. OpenRouter
Using Locust with 10 concurrent users across three text lengths (short/medium/long) I found:
- OpenRouter provided more consistent latency (avg ≈ median) while Anthropic Direct showed high variance (avg 29s vs. median 20s for long texts — a 9-second gap).
- The variance was likely due to Anthropic’s lowest API tier having unpredictable queue times.
- Decision: Stay with OpenRouter for production stability.
Experiment 2: OpenRouter Routing Strategy (sort=latency)
A teammate suggested testing OpenRouter’s sort: latency parameter. I built the test harness ran the experiment and dug into the results:
- No meaningful improvement for medium/long texts.
- The OpenRouter logs revealed both strategies routed to the same provider (Google) — the
sortparameter wasn’t actually changing provider selection for Claude 3.7 Sonnet. - Root cause: Limited active providers for this specific model on OpenRouter’s routing table.
Practical outcomes: I documented that the realistic levers for latency reduction were: (1) prompt optimization to reduce token count (2) upgrading the OpenRouter tier and (3) adding reqeust options discovered by finding provider docs that is suitable for my situation.
Contributing a Bug Fix to LiteLLM
While investigating timeout behavior I discovered that our user-configured timeout values were being silently ignored for OpenRouter requests. Setting timeout=20 should have cut off slow responses at 20 seconds but requests were hanging for up to 300 seconds — aiohttp’s default.
I traced the issue into the LiteLLM source code. In aiohttp_transport.py the ClientTimeout was being constructed with sock_connect sock_read and connect fields — but the total field was never set so it fell back to aiohttp’s 300-second default. This meant every other provider (Anthropic OpenAI Bedrock) respected the configured timeout correctly but OpenRouter — which routes through aiohttp — did not.
I filed issue #16394 with a detailed root cause analysis and submitted PR #16395 with the fix: setting ClientTimeout.total to match the user-configured timeout value using the read component for consistency with how LiteLLM maps its single timeout parameter across all httpx timeout components. The PR included three test cases covering the timeout trigger behavior and was merged into main within a few days.
Shipping Under Constraints
Cost Policy
Early on I noticed the team had no API key management or cost controls. Having been burned by unexpected bills before I raised this with the team lead and pushed for a formal policy. The result: a shared API key management sheet and usage guidelines — simple but essential for a nonprofit with limited budget.
Structured Output Challenges
OpenRouter didn’t support structured outputs for Claude Sonnet or Gemini models. I tried multiple approaches:
- Pydantic
model_json_schema()— generated schemas with unresolved$refreferences requiring complex post-processing. - OpenAI function-call format — needed
anyOf→typeconversions and null field additions. - Each fix introduced new edge cases (e.g. nested
ModifierRelationschema failing to generateproperties).
I eventually abandoned the Pydantic-based schema generation entirely and switched to explicit JSON schema files — manually defined version-controlled and reliable. Sometimes the pragmatic solution beats the elegant one.
Discord Error Bot
During QA testers reported issues via Discord — but I couldn’t always respond immediately (side project day job). I built a Discord monitoring bot that automatically posted detailed error reports. Complete with stack traces request bodies and Langfuse trace links. This wasn’t just a convenience — it was a commitment to continued accountability even after the formal project period ended.
Feature Development
Beyond architecture I continuously shipped features driven by evolving requirements:
- Free/paid user pipeline separation: Different API endpoints with distinct processing pipelines as requested by the product team.
- Model chaining: A
ModelSelectionConstantsclass with rule-based model selection (e.g. vocabulary level C → route to Gemini 2.5 Pro). Rules are prioritized functions easily extensible. - Dynamic prompt assembly: Langfuse prompt versioning with variable injection — strand-level combinations produce different prompts at runtime.
- Fallback model policy: Configured cascading fallbacks with a final fallback to GPT-4o-mini with the policy flagged to leadership for review.
Reflections
What Went Well
- Early architectural investment paid off. The modular design made it straightforward to add the multi-strategy pipeline model chaining and prevention tag handling without touching existing code.
- Cross-team communication was proactive. By understanding the backend codebase myself I could propose DTO changes with full context rather than throwing requirements over the wall.
- Data-driven decisions on latency. Instead of guessing I ran experiments visualized results and presented concrete recommendations.
What I’d Do Differently
- Push harder for distributed tracing early. The OpenTelemetry proposal was solid but got deprioritized. In hindsight even a minimal implementation would have saved debugging time during QA.
- More automated testing earlier. The architecture supported it but time pressure meant we shipped with less test coverage than I wanted.
Working Under Real Constraints
This project taught me what engineering looks like when you can’t throw money or headcount at problems. The nonprofit had limited budget. The team was volunteers with day jobs. Every architectural decision had to account for: Can a future volunteer understand this? Does this add work for web-backend team that’s already stretched thin?
The answer to “what’s the best solution?” was never entirely technical — it was always “what’s the best solution given these constraints?”
Tech Stack
| Layer | Technology |
|---|---|
| API Server | FastAPI Gunicorn |
| LLM Orchestration | LiteLLM Langfuse (prompt mgmt + tracing) |
| Infra | Docker EC2 GitHub Actions CI |
| Testing | Locust (load testing) pytest |
| Monitoring | Langfuse |
Tech for Impact is a technology initiative by Kakao Impact Foundation that matches social innovators with IT professionals for 6-month collaborative projects. Since its inception 618 tech volunteers have participated across 71 projects. If you’re a working engineer in Korea looking for a meaningful way to apply your skills — building real products for real users who need them — I’d highly recommend it.